High-quality, unbiased, uncontaminated benchmarking
DevQualityEval is designed by developers for developers aiming to use LLMs in their workflows. The benchmark evaluates models based on real-world software engineering tasks with a private dataset to avoid contamination.

Focused on LLM usefulness for software development
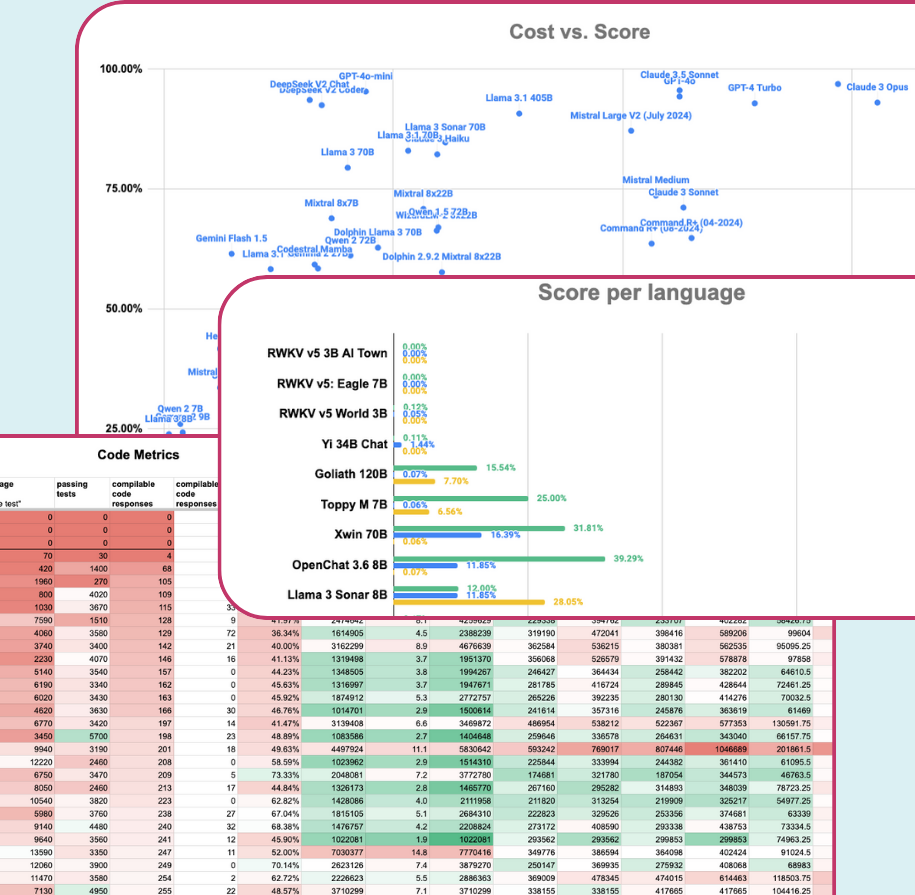
The benchmark helps pinpoint both the best and the most cost-efficient models for various use cases. Our scoring system takes into account factors like output brevity and quality, as well as the cost of generating responses and other metrics.

Up-to-date evaluation of the LLM landscape
We periodically evaluate frontier models and the latest LLMs from various providers to find those that perform best in software engineering tasks. By getting access to our results, you'll stay up-to-date with the state of the art in LLMs.