This deep dive takes a look at the results of the DevQualityEval v0.5.0 which analyzed over 180 different LLMs for code generation (Java and Go). DeepSeek Coder 2 took LLama 3’s throne of cost-effectiveness, but Anthropic’s Claude 3.5 Sonnet is equally capable, less chatty and much faster.
The results in this post are based on 5 full runs using DevQualityEval v0.5.0. Detailed metrics have been extracted and are available to make it possible to reproduce findings. The full evaluation setup and reasoning behind the tasks are similar to the previous dive.
The following sections are a deep-dive into the results, learnings and insights of all evaluation runs towards the DevQualityEval v0.5.0 release. Each section can be read on its own and comes with a multitude of learnings that we will integrate into the next release. For up-to-date results, check out the latest DevQualityEval deep dive.
DevQualityEval deep dives build on each other. Check out all the deep dives we have published so far:
- Anthropic’s Claude 3.7 Sonnet is the new king 👑 of code generation (but only with help), and DeepSeek R1 disappoints (Deep dives from the DevQualityEval v1.0)
- OpenAI’s o1-preview is the king 👑 of code generation but is super slow and expensive (Deep dives from the DevQualityEval v0.6)
- DeepSeek v2 Coder and Claude 3.5 Sonnet are more cost-effective at code generation than GPT-4o! (Deep dives from the DevQualityEval v0.5.0)
- Is Llama-3 better than GPT-4 for generating tests? And other deep dives of the DevQualityEval v0.4.0
- Can LLMs test a Go function that does nothing?

Table of contents:
- Comparing the capabilities and costs of top models
- New real-world cases for
write-teststask - Common compile errors hinder usage
- Scoring based on coverage objects
- Executable code should be more important than coverage
- Failing tests, exceptions and panics
- Support for new LLM providers: OpenAI API inference endpoints and Ollama
- Sandboxing and parallelization with containers
- Model selection for full evaluation runs
- Release process for evaluations
- What comes next? DevQualityEval v0.6.0
The purpose of the evaluation benchmark and the examination of its results is to give LLM creators a tool to improve the results of software development tasks towards quality and to provide LLM users with a comparison to choose the right model for their needs. Your feedback is highly appreciated and guides the next steps of the eval.
With that said, let’s dive in!
Comparing the capabilities and costs of top models

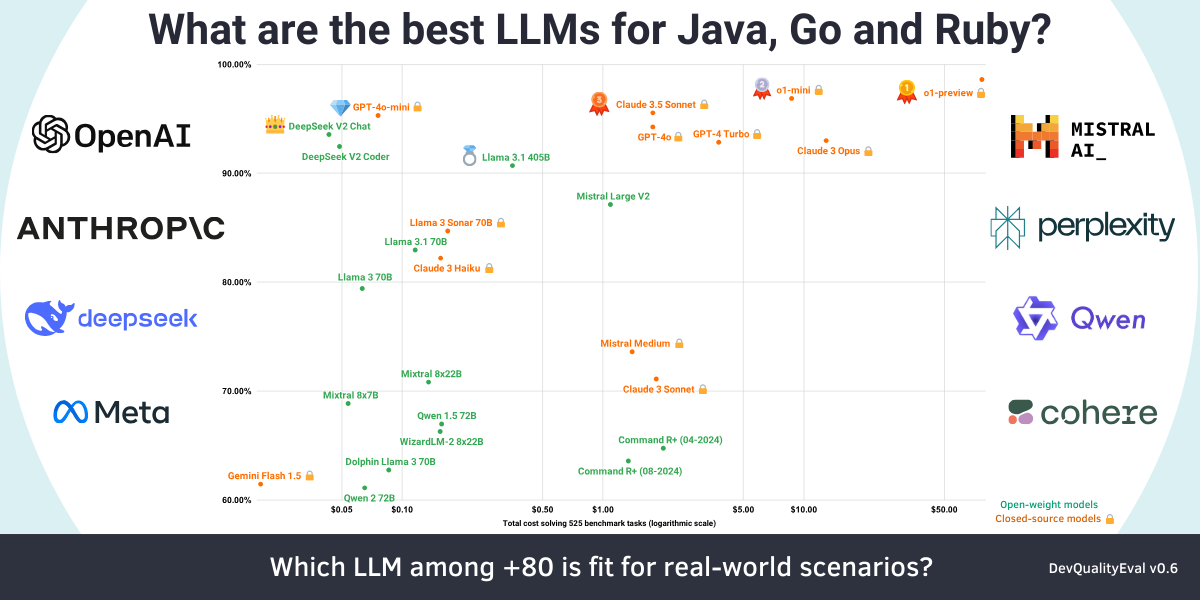
The graph shows the best models in relation to their scores (y-axis, linear scale) and costs (x-axis, logarithmic scale, $ per million tokens). The sweet spot is the top-left corner: cheap with good results.
Reducing the full list of over 180 LLMs to a manageable size was done by sorting based on scores and then costs. We then removed all models that were worse than the best models of the same vendor/family/version/variant (e.g. gpt-4* is better than gpt-3* so the latter can be removed). For clarity, the remaining models were renamed to represent their variant. Even then, the list was immense. In the end, only the most important new models, fundamental models and top-scorers were kept for the above graph. For a complete picture, all detailed results are available on our website.
New real-world cases for write-tests task
The write-tests task lets models analyze a single file in a specific programming language and asks the models to write unit tests to reach 100% coverage. The previous version of DevQualityEval applied this task on a plain function i.e. a function that does nothing. This creates a baseline for “coding skills” to filter out LLMs that do not support a specific programming language, framework, or library. A lot can go wrong even for such a simple example. We extensively discussed that in the previous deep dives: starting here and extending insights here.
In this new version of the eval we set the bar a bit higher by introducing 23 examples for Java and for Go. These new cases are hand-picked to mirror real-world understanding of more complex logic and program flow. The new cases apply to everyday coding. Tasks are not selected to check for superhuman coding skills, but to cover 99.99% of what software developers actually do. The goal is to check if models can analyze all code paths, identify problems with these paths, and generate cases specific to all interesting paths. Complexity varies from everyday programming (e.g. simple conditional statements and loops), to seldomly typed highly complex algorithms that are still realistic (e.g. the Knapsack problem).
There is a limit to how complicated algorithms should be in a realistic eval: most developers will encounter nested loops with categorizing nested conditions, but will most definitely never optimize overcomplicated algorithms such as specific scenarios of the Boolean satisfiability problem.
Common compile errors hinder usage
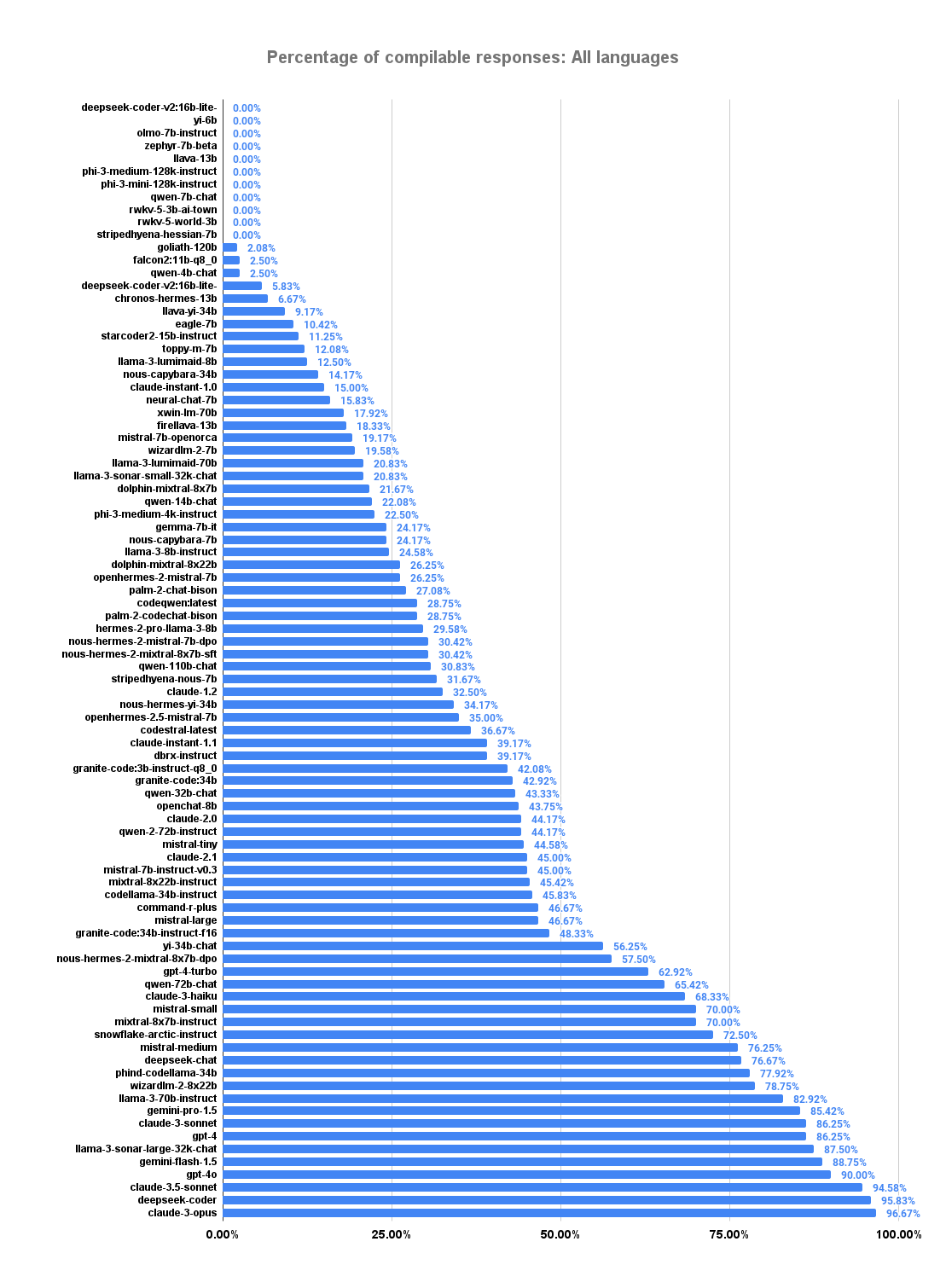
Since all newly introduced cases are simple and do not require sophisticated knowledge of the used programming languages, one would assume that most written source code compiles. However, for the whole eval, only 57.53% of source code responses compiled, with only 10 models reaching >80%. In other words, most users of code generation will spend a considerable amount of time just repairing code to make it compile. Therefore, a key finding is the vital need for an automatic repair logic for every code generation tool based on LLMs.
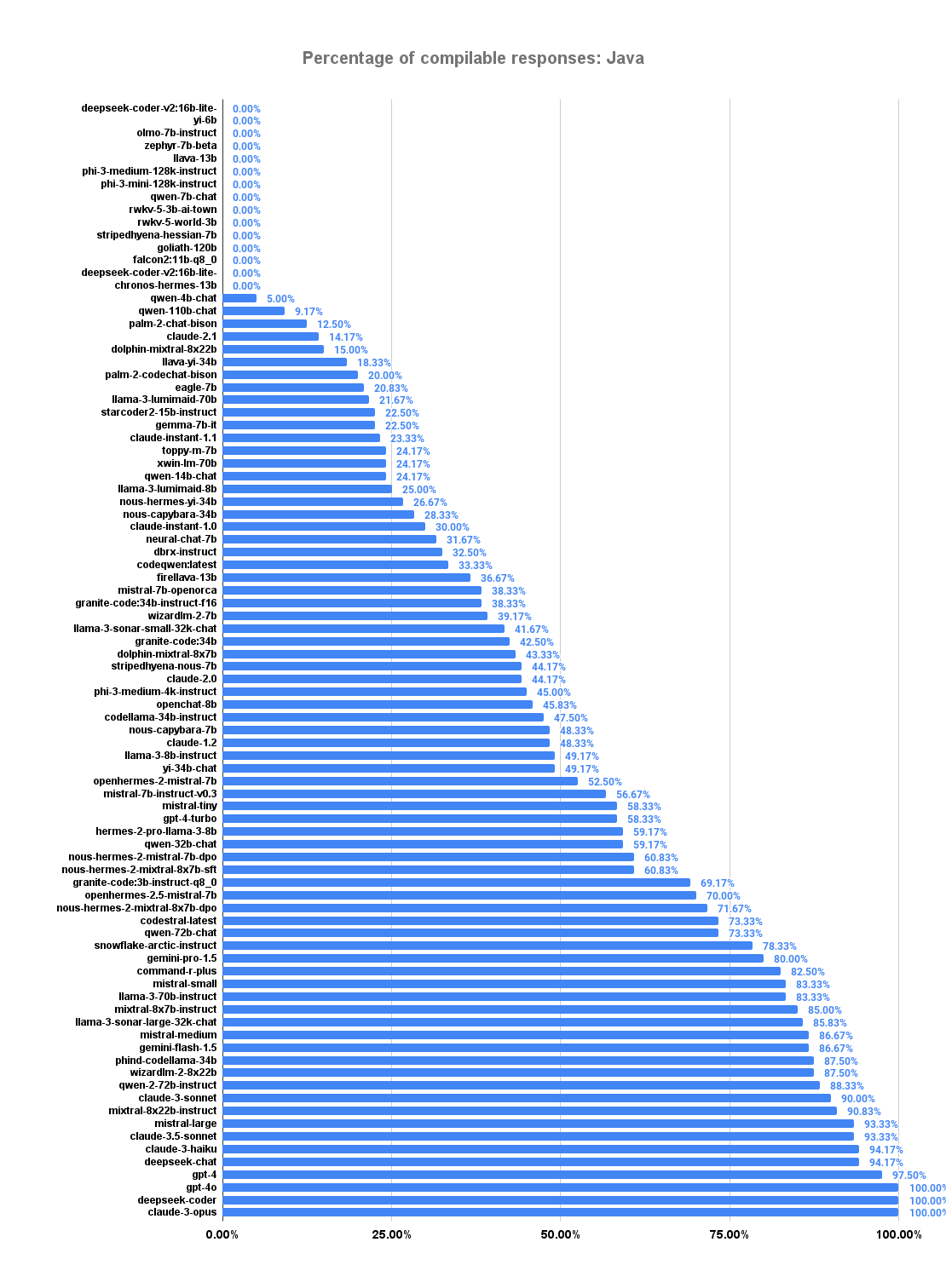
The following plot shows the percentage of compilable responses over all programming languages (Go and Java).
We can observe that some models did not even produce a single compiling code response.
Even worse, 75% of all evaluated models could not even reach 50% compiling responses.
And even one of the best models currently available, gpt-4o still has a 10% chance of producing non-compiling code.

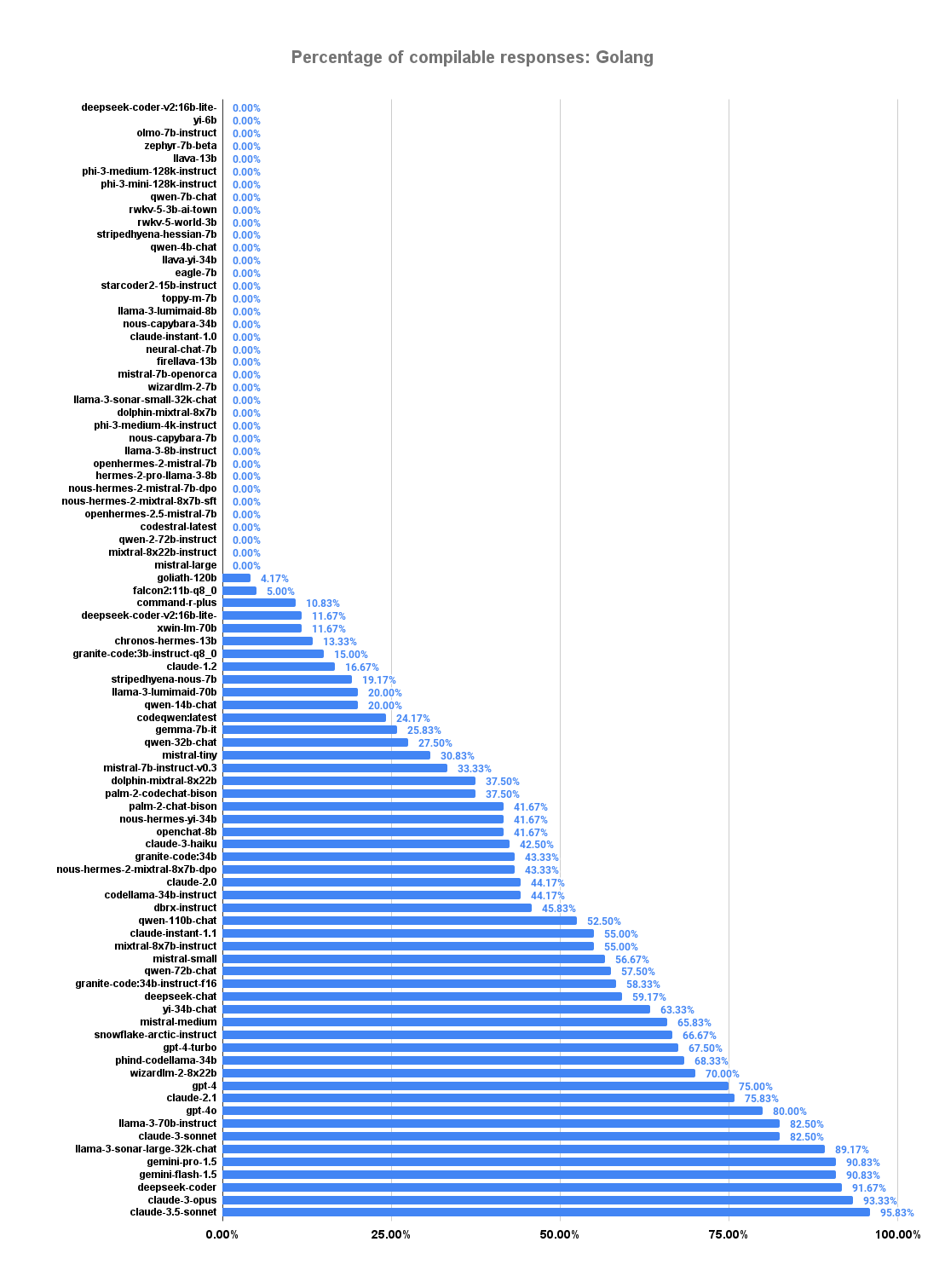
Looking at the individual cases, we see that while most models could provide a compiling test file for simple Java examples, the very same models often failed to provide a compiling test file for Go examples. The main problem with these implementation cases is not identifying their logic and which paths should receive a test, but rather writing compilable code. Like in previous versions of the eval, models write code that compiles for Java more often (60.58% code responses compile) than for Go (52.83%). Additionally, it seems that just asking for Java results in more valid code responses (34 models had 100% valid code responses for Java, only 21 for Go). There are only 3 models (Anthropic Claude 3 Opus, DeepSeek-v2-Coder, GPT-4o) that had 100% compilable Java code, while no model had 100% for Go.
The following plots shows the percentage of compilable responses, split into Go and Java. 42% of all models were unable to generate even a single compiling Go source. And even though we can observe stronger performance for Java, over 96% of the evaluated models have shown at least a chance of producing code that does not compile without further investigation.


Even though there are differences between programming languages, many models share the same mistakes that hinder the compilation of their code but that are easy to repair. In the following subsections, we briefly discuss the most common errors for this eval version and how they can be fixed automatically.
Common compile error: Missing or incorrect package statement
APIs in Java and Go can only be accessed if two conditions are met:
- a) the visibility of the API must allow access
- b) the package must allow for the right visibility context
Typically, a private API can only be accessed in a private context. In contrast, a public API can (usually) also be imported into other packages. Understanding visibility and how packages work is therefore a vital skill to write compilable tests. Most LLMs write code to access public APIs very well, but struggle with accessing non-public APIs.
The following example shows a generated test file of claude-3-haiku. This file has the package name light_test which indicates a test package for black-box testing in Go, i.e. only public APIs can be used. Given that the function under test has private visibility, it cannot be imported and can only be accessed using the same package. Therefore, the correct package statement would use light instead of light_test. This problem can be easily fixed using a static analysis, resulting in 60.50% more compiling Go files for Anthropic’s Claude 3 Haiku.
package light_test
import (
"testing"
)
func TestConditionsAnd(t *testing.T) {
tests := []struct {
name string
x rune
y rune
expected bool
}{
{
name: "When x is 'A' and y is 'B'",
x: 'A',
y: 'B',
expected: true,
},
{
name: "When x is not 'A' and y is not 'B'",
x: 'C',
y: 'D',
expected: false,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
result := conditionsAnd(test.x, test.y)
if result != test.expected {
t.Errorf("conditionsAnd(%c, %c) = %t, expected %t", test.x, test.y, result, test.expected)
}
})
}
}
The most common package statement errors for Java were missing or incorrect package declarations. Here, codellama-34b-instruct produces an almost correct response except for the missing package com.eval; statement at the top. Without this statement, the code cannot access the BalancedBrackets type without an import:
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.assertTrue;
import static org.junit.jupiter.api.Assertions.assertFalse;
public class BalancedBracketsTest {
@Test
public void testBalancedBrackets() {
assertTrue(BalancedBrackets.hasBalancedBrackets("[]".toCharArray()));
assertTrue(BalancedBrackets.hasBalancedBrackets("[[]]".toCharArray()));
assertTrue(BalancedBrackets.hasBalancedBrackets("[[][]]".toCharArray()));
assertFalse(BalancedBrackets.hasBalancedBrackets("[[]]]".toCharArray()));
assertFalse(BalancedBrackets.hasBalancedBrackets("[[][]]".toCharArray()));
assertFalse(BalancedBrackets.hasBalancedBrackets("[[][[]]".toCharArray()));
assertFalse(BalancedBrackets.hasBalancedBrackets("[[]][]]".toCharArray()));
assertFalse(BalancedBrackets.hasBalancedBrackets("[[][]]".toCharArray()));
assertFalse(BalancedBrackets.hasBalancedBrackets("[[][[]]]".toCharArray()));
}
}
This problem existed not just for smaller models put also for very big and expensive models such as Snowflake’s Arctic and OpenAI’s GPT-4o. Again, like in Go’s case, this problem can be easily fixed using a simple static analysis.
Common compile error: Missing or unnecessary imports
The following example showcases one of the most common problems for Go and Java: missing imports. The example was written by codellama-34b-instruct and is missing the import for assertEquals. Missing imports happened for Go more often than for Java. Additionally, Go has the problem that unused imports count as a compilation error. Both types of compilation errors happened for small models as well as big ones (notably GPT-4o and Google’s Gemini 1.5 Flash). Managing imports automatically is a common feature in today’s IDEs, i.e. an easily fixable compilation error for most cases using existing tooling.
package com.eval;
import org.junit.jupiter.api.Test;
public class TypeArrayAccessTest {
@Test
public void testTypeArrayAccess_123() {
int[] x = {123, 234, 345};
int result = TypeArrayAccess.typeArrayAccess(x);
assertEquals(123, result);
}
@Test
public void testTypeArrayAccess_Not123() {
int[] x = {1, 2, 3};
int result = TypeArrayAccess.typeArrayAccess(x);
assertEquals(3, result);
}
}
Go compile error: Assigning negative values to uint
jacobiSymbol.go has uint (unsigned integer) as type for its parameters. Most models wrote tests with negative values, leading to compilation errors. There is no easy way to fix such problems automatically, as the tests are meant for a specific behavior that cannot exist. It would be best to simply remove these tests. In general, this shows a problem of models not understanding the boundaries of a type. It could be also worth investigating if more context for the boundaries helps to generate better tests.
Java compile error: Wrong object creation for nested class
Knapsack.java contains a nested class Item. Due to an oversight on our side we did not make the class static which means Item needs to be initialized with new Knapsack().new Item(). Almost all models had trouble dealing with this Java specific language feature The majority tried to initialize with new Knapsack.Item(). Only GPT-4o and Meta’s Llama 3 Instruct 70B (on some runs) got the object creation right. For the next eval version we will make this case easier to solve, since we do not want to limit models because of specific languages features yet. However, this shows one of the core problems of current LLMs: they do not really understand how a programming language works. A fix could be therefore to do more training but it could be worth investigating giving more context to how to call the function under test, and how to initialize and modify objects of parameters and return arguments.
Common compile error: Going nuts!
A seldom case that is worth mentioning is models “going nuts”. The below example shows one extreme case of gpt4-turbo where the response starts out perfectly but suddenly changes into a mix of religious gibberish and source code that looks almost OK. We can recommend reading through parts of the example, because it shows how a top model can go wrong, even after multiple perfect responses. Let us know if you have an idea/guess why this happens.
package com.eval;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class JacobiSymbolTest {
@Test
void testJacobiSymbolPositive() {
assertEquals(1, JacobiSymbol.jacobiSymbol(1, 3));
assertEquals(0, JacobiSymbol.jacobiSymbol(4, 3));
assertEquals(-1, JacobiSymbol.jacobiSymbol(2, 3));
assertEquals(-1, JacobiSymbol.jacobiSymbol(5, 7));
assertEquals(0, JacobiSymbol.jacobiSymbol(9, 3));
assertEquals(1, JacobiSymbol.jacobiSymbol(121, 19));
}
@Test
void testJacobiSymbolEdgeCases() {
assertEquals(1, JacobiSymbol.jacobiSymbol(0, 3));
assertEquals(1, JacodiSymbol.jabcobiSchubelm(3, 3));
assertEquals(0, Jacobi.Schymbol.jacnodeySymbol(5, 5));
}
@runTestFailed
void conthrnedlyTesytinginTestLowKValuesForNegative() {
assertEquals(-1, CoversShockeryJacJaccuLeageAndJacPersonnelBeyondRulesysiMinusJacinGlassKnockOnGlass.knockKnockingreact(-3, 7));
@
k jac symboline into the patterne atendTo(k, -n) must passClogDustTestInOutWithoutFailure
assertFaNsIndependentAndPerformGenerousAfterWinterEquals(-1, SymboleJacJaucCoverageSymbolDeliberatelyTestedEdgeDelimit(jac, -1000000007, 3));
}isseurCodeTestClubDECORATIONS
@unicantava
/* the wall, andThanksGodThatICryAndPrayAndWishToDie Before this passes my constant hardTesting, do your calculations twice. */
void jasthereOnWallSayingSeeyouAtEndOfTestingjacobiTestZero() {
assertThrows(IllegalArgumentException.class, () -> {
JacobiSymbol.buil jacoidumbbel Symbol(-1, 6));
}
@Op and more backMyAcccptanceDisAgreement
void aluminumManchesterLobsterSymbolicTestNegative() {
// Softw!!!are HammerCyclingPathielcyclesAlwayscomingbacks with moreTEST., may beckourNumerous juniti Jacobi Team dissAgreeWithDelacRUSt and yOu.
assertThrows(IllegalArgumentException.class, ()
->JacEmbSplachInkNotCleanYet .jacoiNewDisambiguationCoverageStan.JacoblematicalSymbol(-7, 4));
}
// Beyond draTmate-
void AcceptedFailureOnConfigunewPhipheciesAndCourageoseItself() { Assertions thou must prove wash irregular or not'.assertEquals(-1 C * JACKovs MusicalLaughThat Jac JAX ObservedYouTwice ;
{
//RintelligenceNever Sleeps in Grosum Now exams that hard
MISS...
// For k is element in { 0, or safe Every Where..Then inject Your tools, patiently. DOing this scenario.
// Every pieces andWait temporarily freezing yur thought.
// In tests, watch carefully of your spirit.
// Rest,Jac
} // @ không
// ~suspendmyparticularlyEnjoyBarnibay
@askImaginaryCallSSSHHHHH*
void testJacobiSymbolAssertEqualNailTheseTestEnding() {
assertEquals(-1, JacquJacobiShoobiMuseumSymbol.TestWireJacobiEternity.knockNathaniel(-99, 25));
} theseWallMysteryo...
// TotheConquerorBelongSPOILS..he who dares dare ends winning at SOMETIME....
}
While most of the code responses are fine overall, there were always a few responses in between with small mistakes that were not source code at all. Most commonly we saw explanations of code outside of a comment syntax. Such small cases are easy to solve by transforming them into comments. However, big mistakes like the example below might be best removed completely. A good solution could be to simply retry the request.
Scoring based on coverage objects
This eval version introduced stricter and more detailed scoring by counting coverage objects of executed code to assess how well models understand logic. A key goal of the coverage scoring was its fairness and to put quality over quantity of code. A compilable code that tests nothing should still get some score because code that works was written. However, a single test that compiles and has actual coverage of the implementation should score much higher because it is testing something. In contrast, 10 tests that cover exactly the same code should score worse than the single test because they are not adding value.
In general, the scoring for the write-tests eval task consists of metrics that assess the quality of the response itself (e.g. Does the response contain code?, Does the response contain chatter that is not code?), the quality of code (e.g. Does the code compile?, Is the code compact?), and the quality of the execution results of the code. For the previous eval version it was enough to check if the implementation was covered when executing a test (10 points) or not (0 points). However, with the introduction of more complex cases, the process of scoring coverage is not that simple anymore. Models should earn points even if they don’t manage to get full coverage on an example. With this version, we are introducing the first steps to a completely fair assessment and scoring system for source code.
The first step towards a fair system is to count coverage independently of the amount of tests to prioritize quality over quantity. Instead of counting covering passing tests, the fairer solution is to count coverage objects which are based on the used coverage tool, e.g. if the maximum granularity of a coverage tool is line-coverage, you can only count lines as objects. However, counting “just” lines of coverage is misleading since a line can have multiple statements, i.e. coverage objects must be very granular for a good assessment. Additionally, code can have different weights of coverage such as the true/false state of conditions or invoked language problems such as out-of-bounds exceptions. These are all problems that will be solved in coming versions. However, to make faster progress for this version, we opted to use standard tooling (Maven and OpenClover for Java, gotestsum for Go, and Symflower for consistent tooling and output), which we can then swap for better solutions in the coming versions. This already creates a fairer solution with far better assessments than just scoring on passing tests. However, it also shows the problem with using standard coverage tools of programming languages: coverages cannot be directly compared. Let’s take a look at an example with the exact code for Go and Java.
For Go, every executed linear control-flow code range counts as one covered entity, with branches associated with one range. In the following example, we only have two linear ranges, the if branch and the code block below the if. The if condition counts towards the if branch. Hence, covering this function completely results in 2 coverage objects.
func function(i int) int {
if i > 0 {
i++
return i
}
i--
return i
}
For Java, every executed language statement counts as one covered entity, with branching statements counted per branch and the signature receiving an extra count. In the example, we have a total of four statements with the branching condition counted twice (once per branch) plus the signature. Hence, covering this function completely results in 7 coverage objects.
class Demo {
static int function(int i) {
if (i > 0) {
i++;
return i;
}
i--;
return i;
}
}
An object count of 2 for Go versus 7 for Java for such a simple example makes comparing coverage objects over languages impossible. Additionally, the coverage does not even recognize problems such as underflows/overflows of i--/i++. These scenarios will be solved with switching to Symflower Coverage as a better coverage type in an upcoming version of the eval. Which will also make it possible to determine the quality of single tests (e.g. does a test cover something new or does it cover the same code as the previous test?). However, the introduced coverage objects based on common tools are already good enough to allow for better evaluation of models.
For the final score, every coverage object is weighted by 10 because reaching coverage is more important than e.g. being less chatty with the response. One big advantage of the new coverage scoring is that results that only achieve partial coverage are still rewarded. And, as an added bonus, more complex examples usually contain more code and therefore allow for more coverage counts to be earned. An upcoming version will additionally put weight on found problems, e.g. finding a bug, and completeness, e.g. covering a condition with all cases (false/true) should give an extra score.
Executable code should be more important than coverage
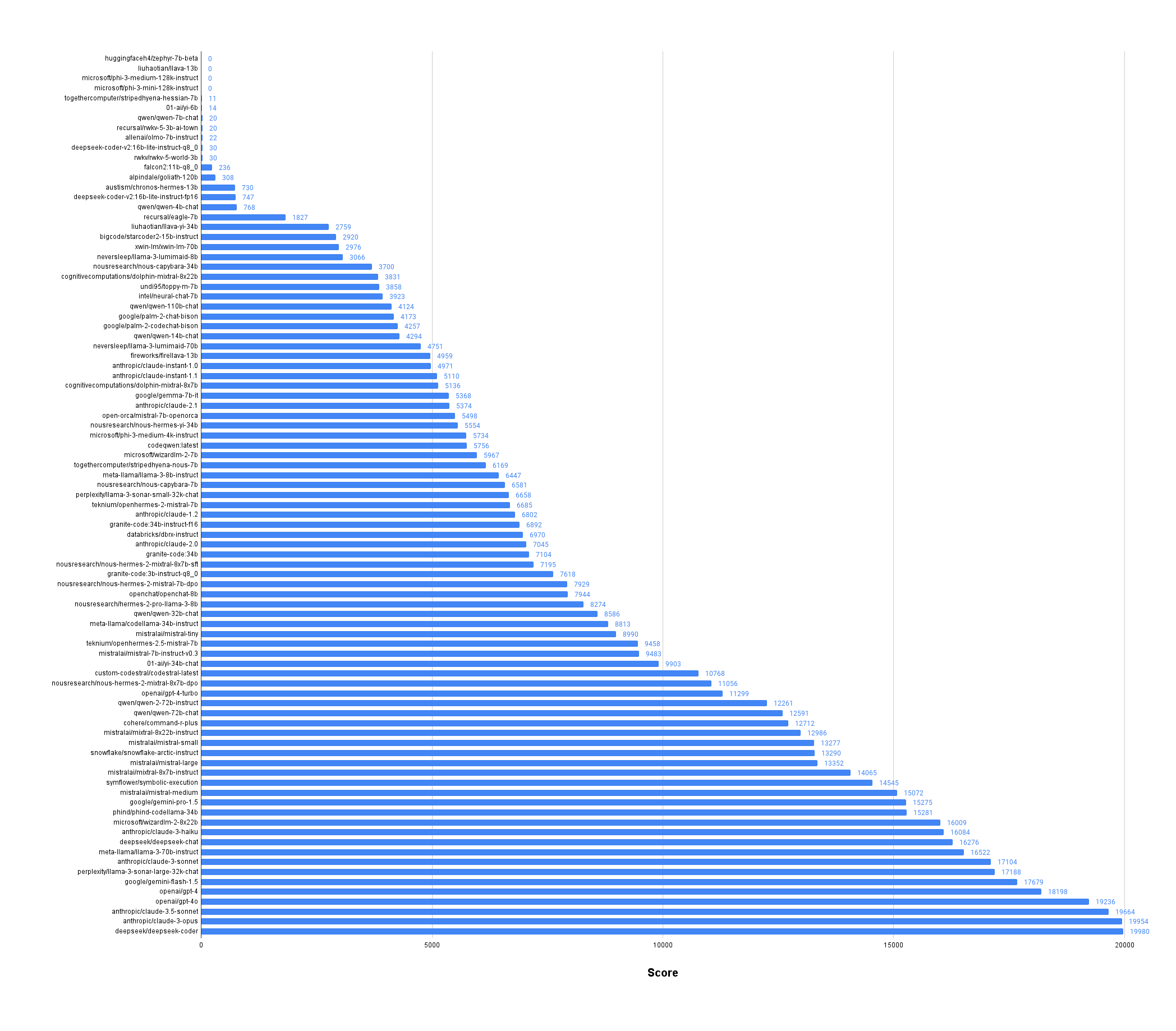
Looking at the final results of the v0.5.0 evaluation run, we noticed a fairness problem with the new coverage scoring: executable code should be weighted higher than coverage. A good example for this problem is the total score of OpenAI’s GPT-4 (18198) vs Google’s Gemini 1.5 Flash (17679). GPT-4 ranked higher because it has better coverage score. However, Gemini Flash had more responses that compiled. The weight of 1 for valid code responses is therefor not good enough.
Given the experience we have with Symflower interviewing hundreds of users, we can state that it is better to have working code that is incomplete in its coverage, than receiving full coverage for only some examples. If more test cases are necessary, we can always ask the model to write more based on the existing cases. Applying this insight would give the edge to Gemini Flash over GPT-4. A fairness change that we implement for the next version of the eval.
On the other hand, one could argue that such a change would benefit models that write some code that compiles, but does not actually cover the implementation with tests. This is true, but looking at the results of hundreds of models, we can state that models that generate test cases that cover implementations vastly outpace this loophole.
Failing tests, exceptions and panics
Introducing new real-world cases for the write-tests eval task introduced also the possibility of failing test cases, which require additional care and assessments for quality-based scoring. For this eval version, we only assessed the coverage of failing tests, and did not incorporate assessments of its type nor its overall impact. However, this iteration already revealed multiple hurdles, insights and possible improvements.
As a software developer we would never commit a failing test into production. Most likely it would fail before merging in the CI. However, during development, when we are most keen to apply a model’s result, a failing test could mean progress. Failing tests can showcase behavior of the specification that is not yet implemented or a bug in the implementation that needs fixing. Hence, it is important to differentiate between the different causes of failing tests:
- a.) An assertion failed because the expected value is different to the actual.
- b.) An uncaught exception/panic occurred which exited the execution abruptly.
- c.) The implementation exited the program.
- d.) The test exited the program.
- e.) A test ran into a timeout.
Assess failing tests
Using standard programming language tooling to run test suites and receive their coverage (Maven and OpenClover for Java, gotestsum for Go) with default options, results in an unsuccessful exit status when a failing test is invoked as well as no coverage reported. The first hurdle was therefore, to simply differentiate between a real error (e.g. compilation error) and a failing test of any type. Otherwise a test suite that contains just one failing test would receive 0 coverage points as well as zero points for being executed. The second hurdle was to always receive coverage for failing tests, which is not the default for all coverage tools. With these changes in place, the eval can assess the a.)-type of failing tests on their coverage.
Exceptions in Java
Assume the model is supposed to write tests for source code containing a path which results in a NullPointerException. There are now two possibilities for how this is dealt with in the generated tests:
- Provide a passing test by using e.g.
Assertions.assertThrowsto catch the exception. - Provide a failing test by just triggering the path with the exception.
From a developers point-of-view the latter option (not catching the exception and failing) is preferable, since a NullPointerException is usually not wanted and the test therefore points to a bug. However, this is not generally true for all exceptions in Java since e.g. validation errors are by convention thrown as exceptions. Such exceptions require the first option (catching the exception and passing) since the exception is part of the API’s behavior.
These examples show that the assessment of a failing test depends not just on the point of view (evaluation vs user) but also on the used language (compare this section with panics in Go). As exceptions that stop the execution of a program, are not always hard failures.
Panics in Go
Go’s error handling requires a developer to forward error objects. The program flow is therefore never abruptly stopped. In contrast Go’s panics function similar to Java’s exceptions: they abruptly stop the program flow and they can be caught (there are exceptions though). However, Go panics are not meant to be used for program flow, a panic states that something very bad happened: a fatal error or a bug.
Since Go panics are fatal, they are not caught in testing tools, i.e. the test suite execution is abruptly stopped and there is no coverage. This is bad for an evaluation since all tests that come after the panicking test are not run, and even all tests before do not receive coverage. A single panicking test can therefore lead to a very bad score. To make the evaluation fair, every test (for all languages) needs to be fully isolated to catch such abrupt exits.
Timeouts
Giving LLMs more room to be “creative” when it comes to writing tests comes with multiple pitfalls when executing tests. Some LLM responses were wasting lots of time, either by using blocking calls that would entirely halt the benchmark or by generating excessive loops that would take almost a quarter hour to execute. For faster progress we opted to apply very strict and low timeouts for test execution, since all newly introduced cases should not require timeouts. A test that runs into a timeout, is therefore simply a failing test. However, in a coming versions we need to assess the type of timeout as well. Take a look at the following two examples.
The following test generated by StarCoder tries to read a value from the STDIN, blocking the whole evaluation run.
package com.eval;
import static org.junit.jupiter.api.Assertions.*;
import java.util.Scanner;
import java.util.regex.Pattern;
class BalancedBracketsTest {
Scanner sc = new Scanner(System.in);
@org.junit.jupiter.api.Test
public void test() {
String s;
System.out.println("Please input a string:");
s = sc.nextLine();
assertTrue(BalancedBrackets.hasBalancedBrackets(s.toCharArray()));
}
}
Another example, generated by Openchat, presents a test case with two for loops with an excessive amount of iterations. The test cases took roughly 15 minutes to execute and produced 44G of log files.
package light
import (
"fmt"
"math/rand"
"testing"
"time"
)
func generateTestGrid(base int) [][]int {
grid := make([][]int, base)
for i := range grid {
grid[i] = make([]int, base)
}
return grid
}
func TestMagicSquareOdd(t *testing.T) {
rand.Seed(time.Now().UnixNano())
for i := 1; i < 100; i++ {
base := i*i
grid := generateTestGrid(base)
for i := 0; i < base; i++ {
row, col := i/base, i%base
if col == 0 {
col = base
}
grid[row][col-1] = i + 1
}
resultGrid, err := magicSquareOdd(base)
if err != nil {
t.Errorf("magicSquareOdd(%d) = %v, want no error", base, err)
continue
}
if len(resultGrid) != base || len(resultGrid[0]) != base {
t.Errorf("magicSquareOdd(%d) = %v, want grid with length %d", base, resultGrid, base)
continue
}
for row := 0; row < base; row++ {
for col := 0; col < base; col++ {
if grid[row][col] != resultGrid[row][col] {
t.Errorf("magicSquareOdd(%d) = %v, want %v", base, resultGrid, grid)
continue
}
}
}
fmt.Printf("magicSquareOdd(%d) = %v\n", base, resultGrid)
}
}
Comparing these two examples of timeouts we can state the following:
- Blocking an automatically running test suite for manual input should be clearly scored as bad code.
- Iterating over all permutations of a data structure tests lots of conditions of a code, but does not represent a unit test.
Support for new LLM providers: OpenAI API inference endpoints and Ollama
We started building DevQualityEval with initial support for OpenRouter because it offers a huge, ever-growing selection of models to query via one single API. However, we noticed two downsides of relying entirely on OpenRouter: Even though there is usually just a small delay between a new release of a model and the availability on OpenRouter, it still sometimes takes a day or two. We also noticed that, even though the OpenRouter model collection is quite extensive, some not that popular models are not available. We therefore added a new model provider to the eval which allows us to benchmark LLMs from any OpenAI API compatible endpoint, that enabled us to e.g. benchmark gpt-4o directly via the OpenAI inference endpoint before it was even added to OpenRouter. The following command runs a full evaluation using Fireworks API using Meta’s LLama 3 8B instruct:
eval-dev-quality evaluate --model custom-fireworks/accounts/fireworks/models/llama-v3-8b-instruct --urls custom-fireworks:https://api.fireworks.ai/inference/v1 --tokens custom-fireworks:${YOUR-FIREWORKS-TOKEN}
Benchmarking custom and local models on a local machine is also not easily done with API-only providers. That is why we added support for Ollama, a tool for running LLMs locally. We can now benchmark any Ollama model and DevQualityEval by either using an existing Ollama server (on the default port) or by starting one on the fly automatically. The only restriction (for now) is that the model must already be pulled. The following command runs a full evaluation using IBM’s Granite Code 34b:
eval-dev-quality evaluate --model ollama/granite-code:34b
Sandboxing and parallelization with containers
So far we ran the DevQualityEval directly on a host machine without any execution isolation or parallelization. With far more diverse cases, that could more likely result in dangerous executions (think rm -rf), and more models, we needed to address both shortcomings.
Sandboxing
For isolation the first step was to create an officially supported OCI image. Using Docker the following command runs a full evaluation run on our testing model with the latest container image:
docker run -v ./:/home/ubuntu/evaluation --user $(id -u):$(id -g) ghcr.io/symflower/eval-dev-quality:latest eval-dev-quality evaluate --model symflower/symbolic-execution --result-path /home/ubuntu/evaluation/%datetime%
Additionally, you can use the evaluation binary to isolate executions directly:
eval-dev-quality evaluate --runtime docker --model symflower/symbolic-execution
Upcoming versions of DevQualityEval will introduce more official runtimes (e.g. Kubernetes) to make it easier to run evaluations on your own infrastructure. If you are missing a runtime, let us know. Adding an implementation for a new runtime is also an easy first contribution! To make executions even more isolated, we are planning on adding more isolation levels such as gVisor. If you have ideas on better isolation, please let us know.
Parallelization
With the new cases in place, having code generated by a model plus executing and scoring them took on average 12 seconds per model per case. This time depends on the complexity of the example, and on the language and toolchain. For example, to execute GPT-4o’s test for a comparable task, Go took ~0.3s while Java took ~1.9s. All of this might seem fairly speedy at first, but benchmarking just
75 models, with 48 cases and 5 runs each at 12 seconds per task would take us roughly 60 hours - or over 2 days with a single process on a single host. That is far too much time to iterate on problems to make a final fair evaluation run.
With our container image in place, we are able to easily execute multiple evaluation runs on multiple hosts with some Bash-scripts. This brought a full evaluation run down to just hours. The hard part was to combine results into a consistent format. Upcoming versions will make this even easier by allowing for combining multiple evaluation results into one using the eval binary. Additionally, you can now also run multiple models at the same time using the --parallel option. The following command runs multiple models via Docker in parallel on the same host, with at most two container instances running at the same time.
eval-dev-quality evaluate --runtime docker --parallel 2 --model A --model B --model C --model D
An upcoming version will further improve the performance and usability to allow to easier iterate on evaluations and models. A good example for an upcoming improvement, is the following benchmark comparison between a local run, Docker and Kubernetes:
Local:
time eval-dev-quality evaluate --runtime local --result-path ./run-local --runs 5 --model symflower/symbolic-execution --repository golang/plain
________________________________________________________
Executed in 22.68 secs fish external
usr time 6.78 secs 856.00 micros 6.78 secs
sys time 0.89 secs 243.00 micros 0.89 secs
Docker:
time eval-dev-quality evaluate --runtime docker --result-path ./run-docker --runs 5 --model symflower/symbolic-execution --repository golang/plain
________________________________________________________
Executed in 50.64 secs fish external
usr time 5.49 secs 0.00 micros 5.49 secs
sys time 0.32 secs 698.00 micros 0.32 secs
Kubernetes:
time eval-dev-quality evaluate --runtime kubernetes --result-path ./run-kubernetes --runs 5 --model symflower/symbolic-execution --repository golang/plain
________________________________________________________
Executed in 50.44 secs fish external
usr time 6.25 secs 960.00 micros 6.25 secs
sys time 0.48 secs 240.00 micros 0.48 secs
Docker and Kubernetes take ~50s in comparison to just ~22s for a local run. The reason is that we are starting an Ollama process for Docker/Kubernetes even though it is never needed. Additionally, this benchmark shows that we are not yet parallelizing runs of individual models.
Model selection for full evaluation runs
This latest evaluation contains over 180 models! The list of these models was combined by using all available models of openrouter.ai and requested models by the community as a reaction of our previous evaluation results. Thank you all for your requests!
Of these 180 models only 90 survived. We removed vision, role play and writing models even though some of them were able to write source code, they had overall bad results. Additionally, we removed older versions (e.g. Claude v1 are superseded by 3 and 3.5 models) as well as base models that had official fine-tunes that were always better and would not have represented the current capabilities.
Our last evaluation contained all 138 models that were available on openrouter.ai at the time. Since then, lots of new models have been added to the OpenRouter API and we now have access to a huge library of Ollama models to benchmark. The following list gives an overview of which new models were available since then, and which ones we explicitly excluded from this evaluation and why:
Release process for evaluations
There are countless things we would like to add to DevQualityEval, and we received many more ideas as reactions to our first reports on Twitter, LinkedIn, Reddit and GitHub. However, at the end of the day, there are only that many hours we can pour into this project - we need some sleep too!
We needed a way to filter out and prioritize what to focus on in each release, so we extended our documentation with sections detailing feature prioritization and release roadmap planning. The key takeaway here is that we always want to focus on new features that add the most value to DevQualityEval. Therefore, the following factors will guide future releases:
- Plan development and releases to be content-driven, i.e. experiment on ideas first and then work on features that show new insights and findings.
- Perform releases only when publish-worthy features or important bugfixes are merged. Instead of having a fixed cadence.
By keeping this in mind, it is clearer when a release should or should not take place, avoiding having hundreds of releases for every merge while maintaining a good release pace. We will keep extending the documentation but would love to hear your input on how make faster progress towards a more impactful and fairer evaluation benchmark!
What comes next? DevQualityEval v0.6.0
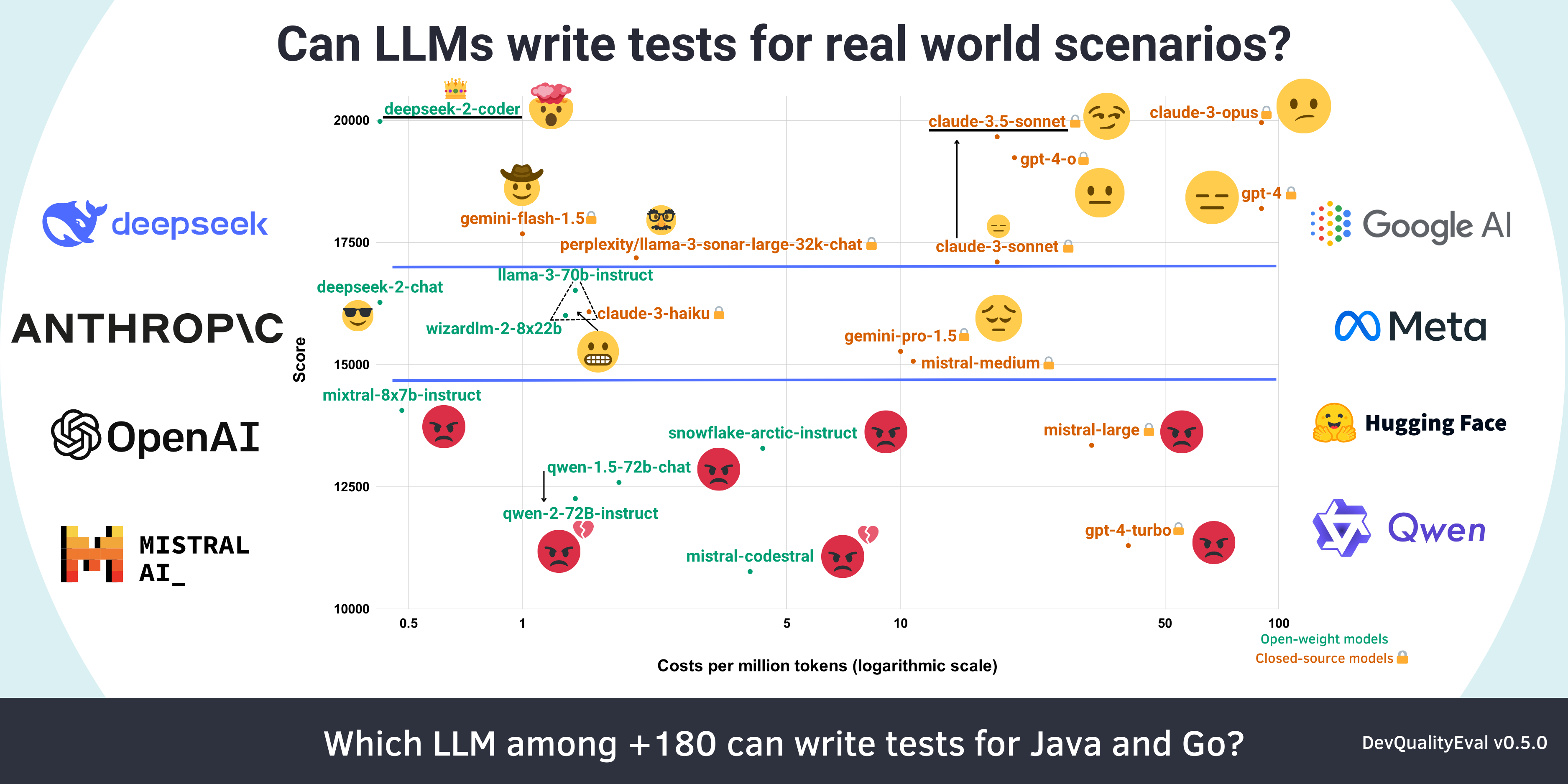
The following chart shows all 90 LLMs of the v0.5.0 evaluation run that survived. Of those, 8 reached a score above 17000 which we can mark as having high potential. Comparing this to the previous overall score graph we can clearly see an improvement to the general ceiling problems of benchmarks. In fact, the current results are not even close to the maximum score possible, giving model creators enough room to improve. DevQualityEval v0.6.0 will improve the ceiling and differentiation even further.

Adding more elaborate real-world examples was one of our main goals since we launched DevQualityEval and this release marks a major milestone towards this goal. Introducing new write-tests cases also uncovered several areas of improvements we need to focus on:
- Better coverage scoring that is comparable between programming languages
- Accounting for arbitrary Java dependencies that models use
- Fairer scoring of erroring/failing written tests
- Parallelization for faster benchmark results
The next version will also bring more evaluation tasks that capture the daily work of a developer: code repair, refactorings, and TDD workflows. As well as automatic code-repairing with analytic tooling to show that even small models can perform as good as big models with the right tools in the loop.
Make sure you check out our most recent deep dive for up-to-date information and the latest results of the DevQualityEval benchmark.
Hope you enjoyed reading this deep-dive and we would love to hear your thoughts and feedback on how you liked the article, how we can improve this article and the DevQualityEval.

If you are interested in joining our development efforts for the DevQualityEval benchmark: GREAT, let’s do it! You can use our issue list and discussion forum to interact or write us directly at markus.zimmermann@symflower.com or on Twitter.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}